Overview:
NoSql Databases vary in architecture and function, so you need to pick the type that is best desired for task
- In general, key-value stores are best for the persistent sharing of data by multiple processes or microservices an application.
- If you plan to do deep relationship analysis for proximity calculation, fraud detection, or evaluation of associative structure, a graph database might be the better choice.
- If you need to collect data very rapidly and at high volumes for analytics, look at a wide column store. Such NoSQL databases tend also to offer document and graph support as well.
NoSQL technology types can be broadly classified into four categories based on their database model implementations as follows:
- Key-Value Stores
As the name suggests, this type of NoSQL database implements a hash table to store unique keys along with the pointers to the corresponding data values. The values can be of scalar datatypes such as integer or complex structures such as JSON, List or BLOB etc. Key-Value stores are simplest type of NoSQL databases to design and implement. Clients can use get, put and delete APIs to read and write data and since they always use primary key access, they very easy to scale and provide high performance.
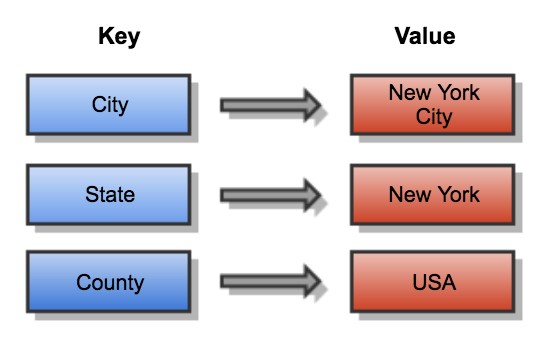
Key-Value stores are ideal for applications with simple data models and require high velocity read & writes.
Sample use cases include:
- Session management
- Profiles, preferences & configurations
- Data Caching
- Storing multimedia files or large objects
Key-Value stores are not suitable when the application requires frequent updates or complex queries involving specific data values, multiple unique keys and relationships between them.
Examples of Key-Value databases include – Redis and Riak.
- Document Stores
Document Stores are similar to Key-Value stores, as there is a key and a corresponding value, but the value provides structure to the stored data in XML, JSON or BSON formats. This value is referred to as a document. Each document is effectively an object containing attribute metadata along with a typed value such as string, date, binary or an array. This provides a way to index and query data based on the attributes in the document.
Document databases have flexible schema, each document can have a different set of attributes. Documents are grouped into containers based on business requirement. Relationships are not stores within such containers and hence, joins are not available in the database. Alternatively, a set of documents can be embedded within a document to provide a level of denormalization.
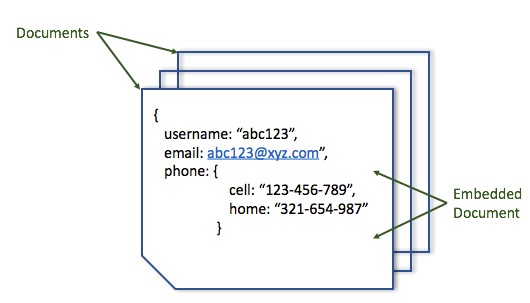
Due to its flexible schema and complex querying capabilities, Document Stores are popular and suitable for variety of use cases such as:
- Content management systems
- E-commerce websites
- Middleware applications that use JSON
Document stores are not suitable if the application requires complex transactions with multiple operations.
Examples of Document Store databases include – MongoDB and Couchbase.
- Column Family Database
In Column Family databases, data is stored in cells of columns, grouped into column families. These databases are implemented as multidimensional nested sorted map of maps. The innermost map constitutes a version of the data identified by a timestamp and stored in a cell. A cell is mapped to a column which in turn is mapped to a column family. A set of column families are identified using a row key. Read and write is performed using the row key on sets of columns. These columns are stored as a continuous entry on the disk enhancing performance.
Column Family databases are designed for large volumes of data requiring high availability and are well-suited for use case such as:
- Time-series data
- IoT applications
- Logging and other write heavy applications
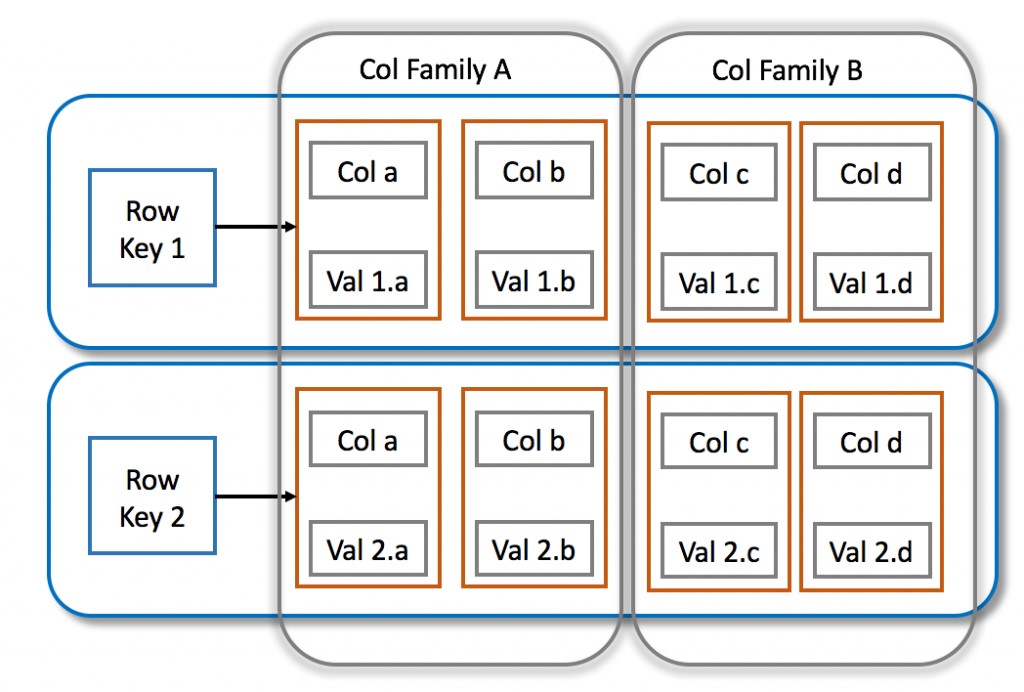
Column Family databases should not be used for applications with ad-hoc query patterns, high level of aggregations and changing database requirements.
Examples of Column Family databases include – HBase and Cassandra.
- Graph Databases (Property Graphs)
A Property Graph consists of nodes and relationships between the nodes. Both nodes and relationships can store number of attributes called properties. Nodes are the entities in the graph and can be tagged with labels which can be used to provide context and metadata to the node. Relationships provide directed, bi-directional and named connections between two nodes. There can be more than one relationship between two nodes and each relationship has a direction, a type, a start node and an end node.
Graph databases can be implemented as a native graph; which means they store data in the graph model described above, while non-native graphs store data in relational or other NoSQL databases such as Cassandra and use graph processing engines for data access. Native Graphs implement index-free adjacency for data access.
Graph database is well-suited for applications traversing paths between entities or where there is need to query the relationship between entities and its properties.
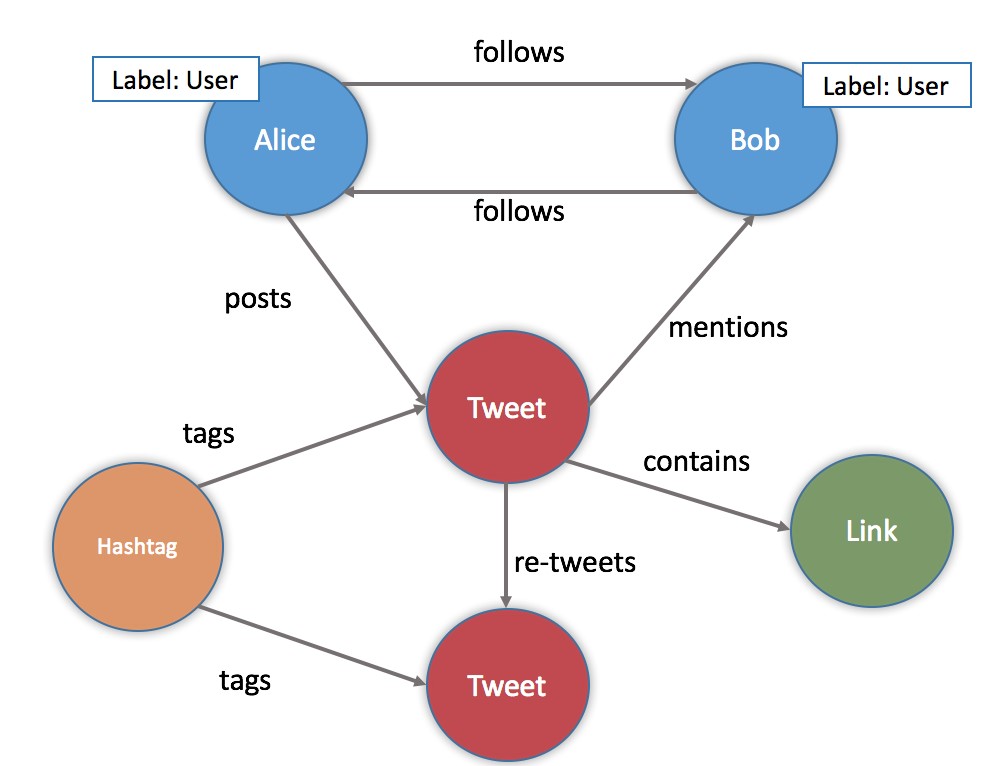
Sample use cases include:
- Location & navigation-based services
- Network and IT infrastructure
- Fraud detection
- Metadata Management
Examples of Graph databases include – Neo4j (native graph) and DSE Search/TitanDB (non-native Cassandra based Graph).
NoSQL Choices Through CAP Theorem:
The CAP Theorem quantifies trade offs between ACID and BASE and states that, in a distributed system, you can only have two out of the following three guarantees: Consistency, Availability, and Partition Tolerance, one of them will not be supported.
- Consistency: All nodes in the cluster have consistent data and a read request returns the most recent write from any node.
- Availability:A non-failing node must always respond to requests in a reasonable time
- Partition Tolerance: System continues to operate during network or node failures.
As per CAP theorem, we must choose from CA, AP or CP characteristics for a given system. This offers a way to categorize databases and provides guidance on determining which database shall be a good fit for your application.
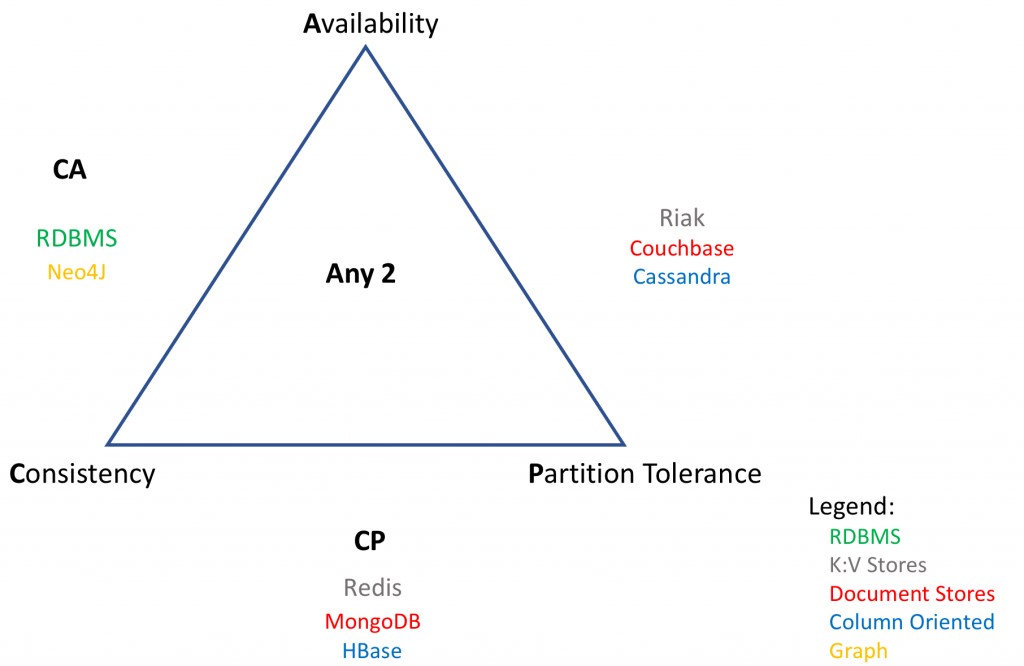
- Consistent and Available System: If your application requires high consistency and availability with no partition tolerance, a CA system is a good fit. Most of the traditional RDBMS are CA systems but we have ruled them out from our fit analysis in stage 1. A Graph Database such as Neo4j is also a CA system and will be analyzed in stage 3 of the fit analysis.
- Consistent and Partition Tolerant System: If your application requires high consistency and partition tolerance, a CP system is a good fit. CP systems are not able to guarantee availability as the system returns error until the partitioned state is resolved. Redis (K:V), MongoDB (Doc Store) and HBase (Col Oriented) are examples.
- Available and Partition Tolerant System: If your application requires high availability and partition tolerance, a AP system is a good fit. AP systems are not able to guarantee consistency as writes/updates can be made to either side of the partition. Such systems usually provide GDHA (Geographically Dispersed High Availability) where data is bi-directionally replicated across two datacenters and both are in Active-Active configuration i.e. application can write/read to/from either datacenter. Riak (K:V), Couchbase (Doc Store) and Cassandra (Col Oriented) are examples.
After analyzing the CAP requirements for your application, you can narrow down to a set of NoSQL databases from the selected CAP category for further consideration.
Determine NoSQL Database Type
As you may have noticed in stage 2, each CAP category contains more than one NoSQL Database types (K:V/Document Store/Column Oriented/Graph). In this stage, we further analyze the application purpose & use case to determine which NoSQL Database type should be considered from the CAP category chosen for your application.
NoSQL Database types are designed for a specific group of use cases. I have listed some of the key use cases for each NoSQL Database type. You can use this list as a starting point for analyzing your application’s requirements.
Choose K:V Stores if:
- Simple schema
- High velocity read/write with no frequent updates
- High performance and scalability
- No complex queries involving multiple keys or joins
Choose Document Stores if:
- Flexible schema with complex querying
- JSON/BSON or XML data formats
- Leverage complex Indexes (multikey, geospatial, full text search etc)
- High performance and balanced R:W ratio
Choose Column-Oriented Database if:
- High volume of data
- Extreme write speeds with relatively less velocity reads
- Data extractions by columns using row keys
- No ad-hoc query patterns, complex indices or high level of aggregations
Choose Graph Database if:
- Applications requiring traversal between data points
- Ability to store properties of each data point as well as relationship between them
- Complex queries to determine relationships between data points
- Need to detect patterns between data points
Now you have decided the CAP category and the NoSQL type for your application. At this stage if we perform a fit analysis based on the select NoSQL databases shown in Fig 1, our decision matrix would look as follows:
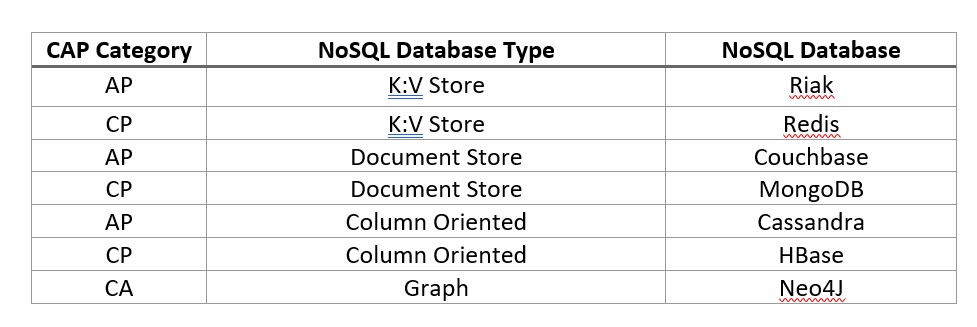
But as a last step, we also need to consider the database and technology characteristics of each NoSQL Database and the requirements from the application and organization to finalize a selection.
MongoDB:
MongoDB is the most popular NoSQL database. A free and open source, cross-platform, document-oriented database, MongoDB uses JSON-like documents with schemas.
The cloud-based offering handles database management, setup and configuration, software patching, monitoring, and backups, and it operates as a distributed database cluster.
Key features and capabilities:
Fully managed backup, continuous backup, point-in-time recovery, query able snapshots, automatically generated charts, a real-time performance panel, and customizable alerting. Users can import live data to MongoDB Atlas with minimal impact to applications, using the built-in Live Migration Service.
Use Cases:
personalization, real-time analytics, internet of things (IoT), big data, product/asset catalogs, security and fraud detection, mobile applications, data hubs, content management, and social and collaboration applications.
Amazon DynamoDB:
Amazon DynamoDB is another popular cloud-based NoSQL database. Amazon DynamoDB is a fully managed NoSQL platform that uses a solid-state drive (SSD) to store, process, and access data to support high performance and scale-driven applications.
It automatically shards data across servers based on the workload’s throughput and storage requirements, and handles larger high-performance use cases.
Users can scale, monitor, and manage their tables both via application programming interfaces (APIs) and the Amazon Web Services Management Console. DynamoDB is tightly integrated with Amazon EMR (a managed framework for Apache Hadoop, Apache Spark, and HBase) that offers the ability to run queries that span multiple data sources.
The platform supports both key-value and document models and also has a library for geospatial indexing. Organizations use DynamoDB to support
Use Cases:
including advertising campaigns, social media applications, tracking gaming information, collecting and analyzing sensor and log data, and e-commerce.
Cassandra:
DataStax leverages Apache Cassandra for distribution across data centres. A strong plus for DataStax NoSQL has been its global distributed architecture. DataStax distributes, contributes to, and supports the commercial enterprise version of Apache Cassandra, an open source project. Cassandra is a wide-row store, distributed key-value database based on Google Bigtable.
Among its key features are fault tolerance, scale-out architecture, low-latency data access, and simplified administration. DataStax provides additional features such as analytics, search, monitoring, in-memory, and security to support critical applications.
DataStax Enterprise supports various types of business applications, including transactional, analytical, predictive analytics, and mixed workloads. It offers broader multi-model capabilities with support for graph and JSON data.
Use Cases:
include fraud detection, product catalogues, consumer personalization, recommendation engines, and IoT.
Couchbase:
Couchbase is a JSON document support database platform distributed by Couchbase Inc. The open source NoSQL DBMS supports broad use cases.
Couchbase Server, an open source NoSQL key-value and document database with built-in cache, appeals to enterprises that need a database that can deliver performance, multi-model, scale, and automation.
Organizations use Couchbase to support social and mobile applications, content and metadata stores, e-commerce transactions, and online gaming applications. Couchbase provides full support for documents, flexible data model, indexing, full-text search, and MapReduce for real-time analytics.
The platform is used by large enterprises to support various critical workloads, including operational and analytical processes.
Redis Enterprise:
Sponsored by Redis Labs, open source platform Redis Enterprise is one of the most common key-value NSQ databases, says IDC’s Olofson. (Learn more at InfoWorld about using Redis for real-time metering, managing access control, and traffic-shaping WebSockets.)
Redis offers a high-performing, in-memory database that supports both relaxed and strong consistency, a flexible schema less model, high availability, and ease of deployment.
Redis Labs developed additional features and technology that encapsulates the open source software and provides an enhanced deployment architecture for Redis, while supporting the open source API.
The data model supports key-value; a variety of data structures such as lists, sets, bitmaps, and hashes; and a range of models through pluggable modules such as search, graph, JSON, and XML.
Use Cases:
Including real-time analytics, transactions, data ingestion, social media, job management, message queuing, and caching.
Select NoSQL Database (Vendor)
Even after selecting a CAP category and NoSQL Database type, the fit analysis is not complete. Selection of a NoSQL Database also depends on the database technology, its configuration and available infrastructure, proposed architecture of your application, budget as well as the skill set available at your organization etc.
Database considerations:
- Backup and recovery configurations
- Cluster topology: GDHA / HADR, Active-Active / Active-Passive
- Replication: Synchronous, Asynchronous or Quorum
- Read/Write concerns and Indexing strategies
- Concurrency control: Locks, MVCC (Multi Version Concurrency Control), Read Your Own Write (RYOW)
- Security, access controls and encryption at rest
- Available APIs and Query methods: JSON, XML, REST, Thrift, CQL, MapReduce, SPARQL, Cypher, Gremlin etc.
- Infrastructure: On-premise or Cloud / Dedicated or Shared
- Database uptime categorization (99.9% up to 99.999%)
Architecture/Application considerations:
- Application Requirements: Use cases, R:W patterns, performance expectations/SLAs, upstream/downstream systems, criticality to the business etc.
- Implementation Language and SDKs: C/C++, Java, Python, Node.Js etc
- Application Architecture: Web Application, Microservices, Mobile etc.
- Data Integration: Batch processing, ETL, Streaming, Message broker, ESB etc.
- Complementary Technologies: Spark, Storm, Kafka, ELK, Solr, Splunk etc.
Organization considerations:
- Budget and cost considerations
- Team skillset
- Preferred vendors / existing technology stack
- Motivation for NoSQL/Big Data
- Business / Technology leadership sponsorship & support
